.png)
基数
在数学上,基数或势,即集合中包含的元素的“个数”(参见势的比较),是日常交流中基数的概念在数学上的精确化(并使之不再受限于有限情形)。有限集合的基数,其意义与日常用语中的“基数”相同,例如{{a,b,c}的基数是3。无限集合的基数,其意义在于比较两个集的大小,例如整数集和有理数集的基数相同;整数集的基数比实数集的小。
在介绍HyperLogLog的原理之前,请你先来思考一下,如果让你来统计基数,你会用什么方法。
set
熟悉Redis数据结构的同学一定首先会想到Set这个结构,我们只需要把数据都存入Set,然后用scard命令就可以得到结果,这是一种思路,但是存在一定的问题。如果数据量非常大,那么将会耗费很大的内存空间,如果这些数据仅仅是用来统计基数,那么无疑是造成了巨大的浪费,因此,我们需要找到一种占用内存较小的方法。
bitmap
bitmap同样是一种可以统计基数的方法,可以理解为用bit数组存储元素,例如01101001,表示的是[1,2,4,7],bitmap中1的个数就是基数。bitmap也可以轻松合并多个集合,只需要将多个数组进行异或操作就可以了。bitmap相比于Set也大大节省了内存,我们来粗略计算一下,统计1亿个数据的基数,需要的内存是:100000000/8/1024/1024 ≈ 12M。
虽然bitmap在节省空间方面已经有了不错的表现,但是如果需要统计1000个对象(每个对象统计1亿基数),就需要大约12G的内存,显然这个结果仍然不能令我们满意。在这种情况下,HyperLogLog将会出来拯救我们。
> setbit testbitmap 1 1
0
> setbit testbitmap 2 1
0
> setbit testbitmap 4 1
0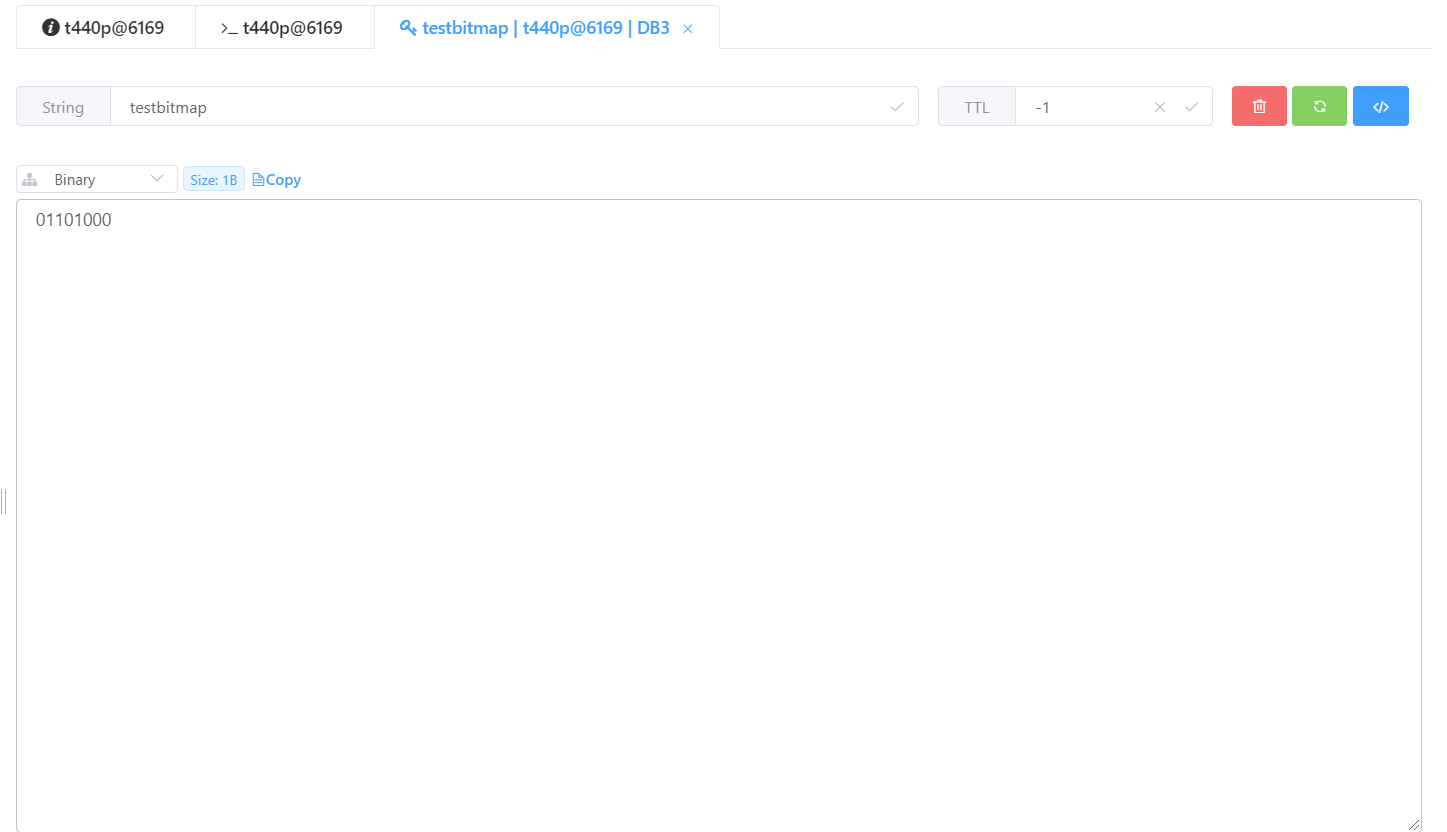
> setbit testbitmap 8 1
0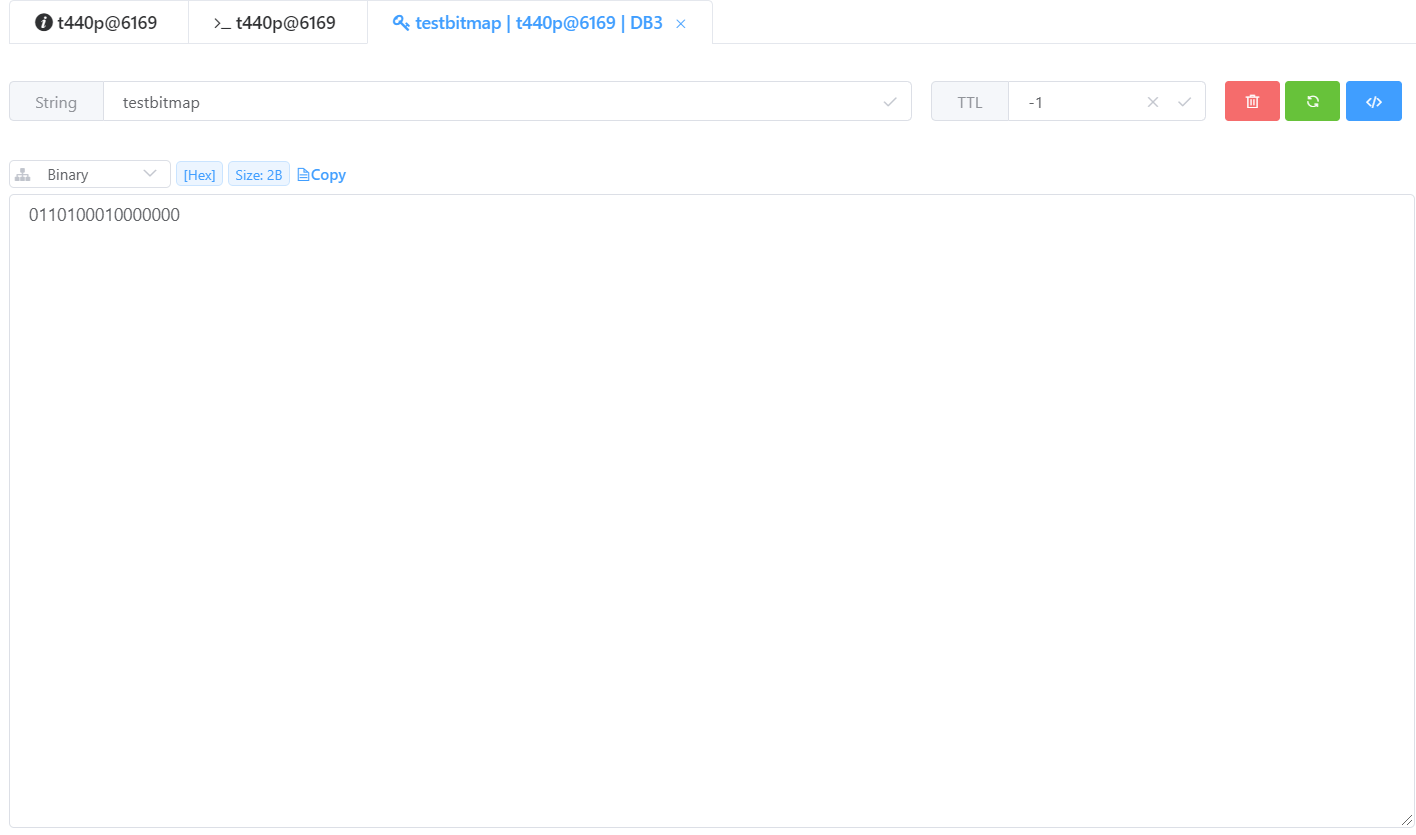
HyperLogLog王者方案
❝ Set 虽好,如果文章非常火爆达到千万级别,一个 Set 就保存了千万个用户的 ID,页面多了消耗的内存也太大了。
同理,Hash数据类型也是如此。
至于 Bitmap,它更适合于「二值状态统计」的使用场景,统计精度高,虽然内存占用要比HashMap少,但是对于大量数据还是会占用较大内存。
咋办呢?
这些就是典型的「基数统计」应用场景,基数统计:统计一个集合中不重复元素的个数。
HyperLogLog 的优点在于它所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog进行计算所需的内存总是固定的,并且是非常少的。
每个 HyperLogLog 最多只需要花费 12KB 内存,在标准误差 0.81%的前提下,就可以计算 2 的 64 次方个元素的基数。
演示样例
HyperLogLog 使用太简单了。PFADD、PFCOUNT、PFMERGE三个指令打天下。
PFADD
将访问页面的每个用户 ID 添加到 HyperLogLog 中。
PFADD Redis主从同步原理:uv userID1 userID 2 useID3
PFCOUNT
利用 PFCOUNT 获取 「Redis主从同步原理」文章的 UV值。
PFCOUNT Redis主从同步原理:uv
PFMERGE 使用场景
HyperLogLog` 除了上面的 `PFADD` 和 `PFCOIUNT` 外,还提供了 `PFMERGE
语法
PFMERGE destkey sourcekey [sourcekey ...]
比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。
其中页面的 UV 访问量也需要合并,那这个时候 PFMERGE 就可以派上用场了,也就是同样的用户访问这两个页面则只算做一次。
如下所示:Redis、MySQL 两个 HyperLogLog 集合分别保存了两个页面用户访问数据。
PFADD Redis数据 user1 user2 user3
PFADD MySQL数据 user1 user2 user4
PFMERGE 数据库 Redis数据 MySQL数据
PFCOUNT 数据库 // 返回值 = 4
将多个 HyperLogLog 合并(merge)为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合(observed set)的并集。
user1、user2 都访问了 Redis 和 MySQL,只算访问了一次。
hyperloglog原理
HyperLogLog实际上不会存储每个元素的值,它使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量。这么说不太容易理解,容我先搬出来一个栗子。
有一天Jack和丫丫玩抛硬币的游戏,规则是丫丫负责抛硬币,每次抛到正面为一回合,丫丫可以自己决定进行几个回合。最后需要告诉Jack最长的那个回合抛了多少次,再由Jack来猜丫丫一共进行了几个回合。Jack心想:这可不好猜啊,我得算算概率了。于是在脑海中绘制这样一张图。
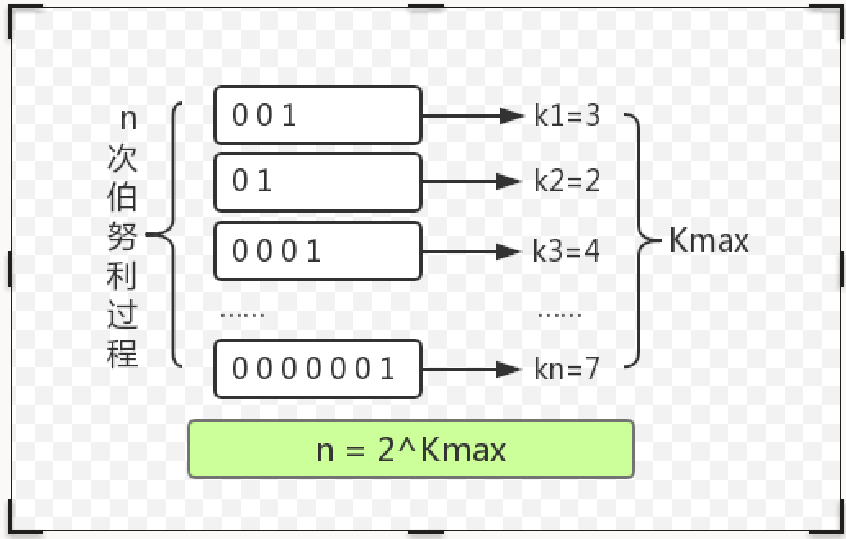
后面参照这里:
走近源码:神奇的HyperLogLog - 知乎 (zhihu.com)
HyperLogLog 算法详解 - 知乎 (zhihu.com)
关于geo类型的使用参照这里: